

Data Citation WG
Group Organizers
- Organized by
-
-
WGDC Pilot CSV Reference
-
Discussion
-
CSV Reference Implementation
– Pilot name: CSV Reference Implementation
– Contact person: Stefan Pröll
– Type: research pilot
– Status: active
– Type of data: CSV
– Dynamics: frequent (daily/hourly)
– Domain: Generic
– Short description: Make subsets from generic CSV data citable.
– Solution / approach: Import CSV data into RDBMS (MySQL) and automatically version files. Users interact via Web interface and select subset. The queries are transparently captured in the Query Store
– Timeline: 2015 – 2016
– Supplementary material:- Stefan Proell and Andreas Rauber, “A Scalable Framework for Dynamic Data Citation of Arbitrary Structured Data,” in 3rd International Conference on Data Management Technologies and Applications (DATA2014), 2014. PDF
- Prototype at Github
- MySQL-Prototype are below and a screencast can be found at http://www.datacitation.eu
RDA Data Citation Recommendations and their Application in the CSV Reference Implementation
The goal of the CSV research prototype is to allow users to upload individual and previously unknown CSV files to the system via their browser and let them select precise subsets of the data, even when the data is evolving. Users are able to retrieve a subset exactly as it was when they generated the subset, although the source data was updated meanwhile. We implemented the CSV use case from scratch within the Java 8 stack for the front end and the backend, the data is managed and stored with a MySQL 5.7 database system. The CSV prototype migrates the data automatically into a relational database schema and implements versioning and timestamping for the data. Users can specify any subset of their CSV data by selecting and filtering the data by using a Web interface. The system stores the way how the data subset was selected, including the timing and versioning information, allowing to retrieve any version of this subset at any time, even when the source data set is changing. In the following, we provide details how the RDA Recommendations for the Citation of Dynamic Data are implemented in the CSV pilot and how we interpreted the recommendation within the context of the pilot implementation.
A. Preparing the Data and the Query Store
- R1 – Data Versioning: For retrieving earlier states of data sets the data needs to be versioned.
The CSV data sets are uploaded by the user via a Web form and the system migrates the data automatically into a relational database schema. As soon as a record (a row in the CSV file) enters the system, a timestamp is assigned and the record is marked as inserted in the database. Users can upload corrections of their CSV file, by providing a new CSV file containing the changes of the data. The system automatically detects which records are identical and which records are new, missing or changed. Based on this detection, the system can update modified records and assign a new timestamp for this update. It is noteworthy, that an update does not overwrite existing data, but rather marks the old record in the database as outdated and inserts a new record having a new timestamp. The same is true for deletions, as records are (in our scenario) never actually deleted but rather marked as deleted in the system. We keep this old versions and are therefore able to retrieve exactly the same data set again as it was at a specified point in time, by using the timestamp of the data and the query (see next recommendation R2).
- R2 – Timestamping: Ensure that operations on data are timestamped, i.e. any additions, deletions are marked with a timestamp.
Whenever new data enters the system, existing data gets modified or deleted, each of this operation triggers two things. Firstly, the old record’s status gets updated, i.e. a record gets marked as deleted or as updated or as inserted. This captures the type of operation and allows us to exclude for instance records marked as deleted from future queries. Secondly, each of these operations gets the timestamp of the execution of the operation assigned. This allows us to map a specific state of the data to the query, which is executed at as a specific point in time. In our scenario, we utilise MySQL timestamps, which have a resolution of seconds (fractions of seconds would be possible too).
- R3 – Query Store: Provide means to store the queries used to select data and associated metadata.
The query store is a central infrastructure for our approach and has been implemented from scratch as well. The query store is responsible for storing the metadata of each query, which was used for creating a subset. In our scenario, subsets are expressed by SQL SELECT statements on the MySQL database back end. The user interacts with a simple Web interface, where she can specify which columns of a CSV file to include into a subsets and which filters to be applied, in order to limit the result to the desired outcome. The query store receives this selection criteria from the Web interface and stores them persistently within the Query Store. In addition to the query parameters, the Query Store also stores the execution time of the query, the user who executed the query and a persistent identifier for each query.
B. Persistently Identify Specific Data sets
When a data set should be persisted, the following steps need to be applied:- R4 – Query Uniqueness: Re-write the query to a normalised form so that identical queries can be detected. Compute a checksum of the normalized query to efficiently detect identical queries.
The Web interface delivers consistent queries for each selection process, each query has the very same structure. For this reason we can sort the query parameters for instance alphabetically and therefore compute a hash (SHA1) of the query parameters. This allows us to detect identical queries with confidence, based on the query interface and the query store. Each new query, which has not yet been queried, gets a new persistent identifier (PID) assigned. If a query has been issued before, we only assign a new PID, if and only if the result set is different, meaning that the data has changed between the two executions of the identical query. This issue is further explained in R6.
- R5 – Stable Sorting: Ensure an unambiguous sorting of the records in the data set.
Sorting is essential in order to retrieve the very same data set or subset again, as SQL per se does not guarantee the sequence of results if the users does not explicitly specify a sorting in the query. Our system requires the user to specify a primary key. A primary key is a database concept which (in abbreviated essence) allows to detect a record uniquely, for instance by some sort of id column. Most data sets do have some form of primary key. Where a user fails to provides such a key column, our system automatically generates an artificial primary key based on the insertion sequence number. We then use the primary key column always as the defined sorting, unless the user overwrites this setting with a custom sorting in the Web interface. With this technique, we can ensure stable sorting for all kinds of data sets.
- R6 – Result Set Verification: Compute a checksum of the query result set to enable verification of the correctness of a result upon re-execution.
We also need to verify whether a result has changed or not, as already described in R4. For each subset creation process, we compute a hash of the query result and store this hash key in the query store together with the query metadata. We can use this information in order to detect if the data has been changed between two executions of identical queries or to verify that the result is still the same when a query is re-executed. For performance reasons, we compute the has key based on the column names included in a result set and based on the sequence of the primary keys within the result set. This reduces the required time considerably, as the input for the hash function is much smaller. Higher precision for the result set verification can be achieved by computing the hash key for the full result set.
- R7 – Query Timestamping: Assign a timestamp to the query either based on the last update to the entire database or the last update to the selection of data affected by the query or the query execution time. This allows retrieving the data as it existed at query time.
There are several possibilities of assigning the query timestamp. In our scenario, we assign the server time of the query execution to the query as updates are infrequent and data sets usually relatively small (< 1 million records). We have the metadata columns indexed as well for the data and for the query store. This allows us to retrieve the data in a timely fashion even for million records.
- R8 – Query PID: Assign a new PID to the query if either the query is new or if the result set returned from an earlier identical query is different due to changes in the data. Otherwise, return the existing PID.
The decision process whether or not to assign a new PID to a query is rather simple in our prototype implementation. We detect existing queries by using their query hash (R4). If a query is new, we assign a new PID immediately. If the query has been detected earlier, we verify if the result set changed, based on the hash key of the result set (R8). If this result changed, we assign a new PID to indicate this updated result.
- R9 – Store Query: Store query and metadata (e.g. PID, original and normalised query, query & result set checksum, timestamp, superset PID, data set description and other) in the query store.
We store all the query metadata in a dedicated query store database schema. The query store keeps track of the existing data sets (which have been CSV files once) and it stores metadata about the data set, such as the last update or the amount of active records. For each query, which is used to generate a subset, we store the query parameters, timing information, parent data set PID, assigned PID, hash keys etc in the database schema. The query store itself is versioned, which allows to make corrections and trace them.
- R10 – Citation Text: Provide a recommended citation text and the PID to the user.
For enhancing the convenience of our implementation for the users, we automatically create a text snipped for users to copy and paste into their reports. The text snipped is generated from the query store data and displayed on a landing page. The text contains author and title of the data set, PID and parent PID as well as the date of execution.
C. Upon Request of a PID
- R11 – Landing Page: PIDs should resolve to a human readable landing page of the data set, which provides metadata including a link to the superset (PID of the data source) and citation text snippet.
As soon as a data set or a subset has been uploaded or generated by a user, the interface presents a clickable link containing the URL of the landing page of the data set. The system also provides a resolver service and API for retrieving the landing page data from a provided PID. In addition, the citation text (R11) is displayed and can be copied into reports.
- R12 – Machine Actionability: the landing page should be machine-actionable and allow retrieving the data set by re-executing the timestamped query.
The landing page provides several buttons for the user, where she can obtain the subset in the version described on the landing page, she can also obtain the most recent version of the same data set or the parent data set as well. Upon clicking on one of these buttons, the system re-executes the query automatically in the background and writes the result set back into a CSV file which can be downloaded by the user. The same functionality can be achieved programatically by the API of the system.
D. Upon Modifications to the Data Infrastructure
- R13 – Technology Migration: When data is migrated to a new representation (e.g. new database system, a new schema or a completely different technology), the queries and associated checksums need to be migrated.
We decided to keep the system as simple as possible. The data can be easily migrated into open formats, other database systems or even plain CSV text. As the data is self-describing, interpretation is simple, as all that is required is a mapping between the query (which consists of selected columns and filters) to the most recent version time stamp of the data tables. As we have the query parameters available in the query store, the queries can be migrated into a different system by applying the parameters in a different query language. We do not use database specific operations, but only rely on projection and selection within SELECT statements.
- R14 – Migration Verification: Successful query migration should be verified by ensuring that queries can be re-executed correctly.
Having the hash keys of the result sets available, we can verify that the result sets are still identical. Depending on the target language, updating the query hashes to match the new languages is a requirement, which can be addressed by re-computing the new hash keys and comparing the result sets.
MySQL-Prototype
The following MySQL-Prototype show the interface of the prototype implementation.
Login Page
Users need to login. Each user account is mapped to an organisation, which determines the prefix of the persistent identifier.
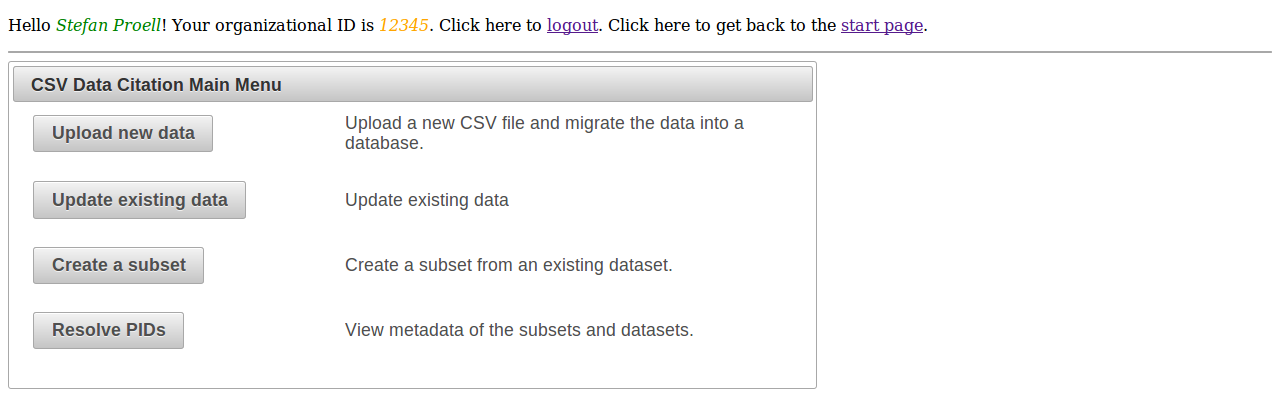
Main Menu
The main menu allows users to upload new files, update existing data sets, create subsets and resolve PIDs.
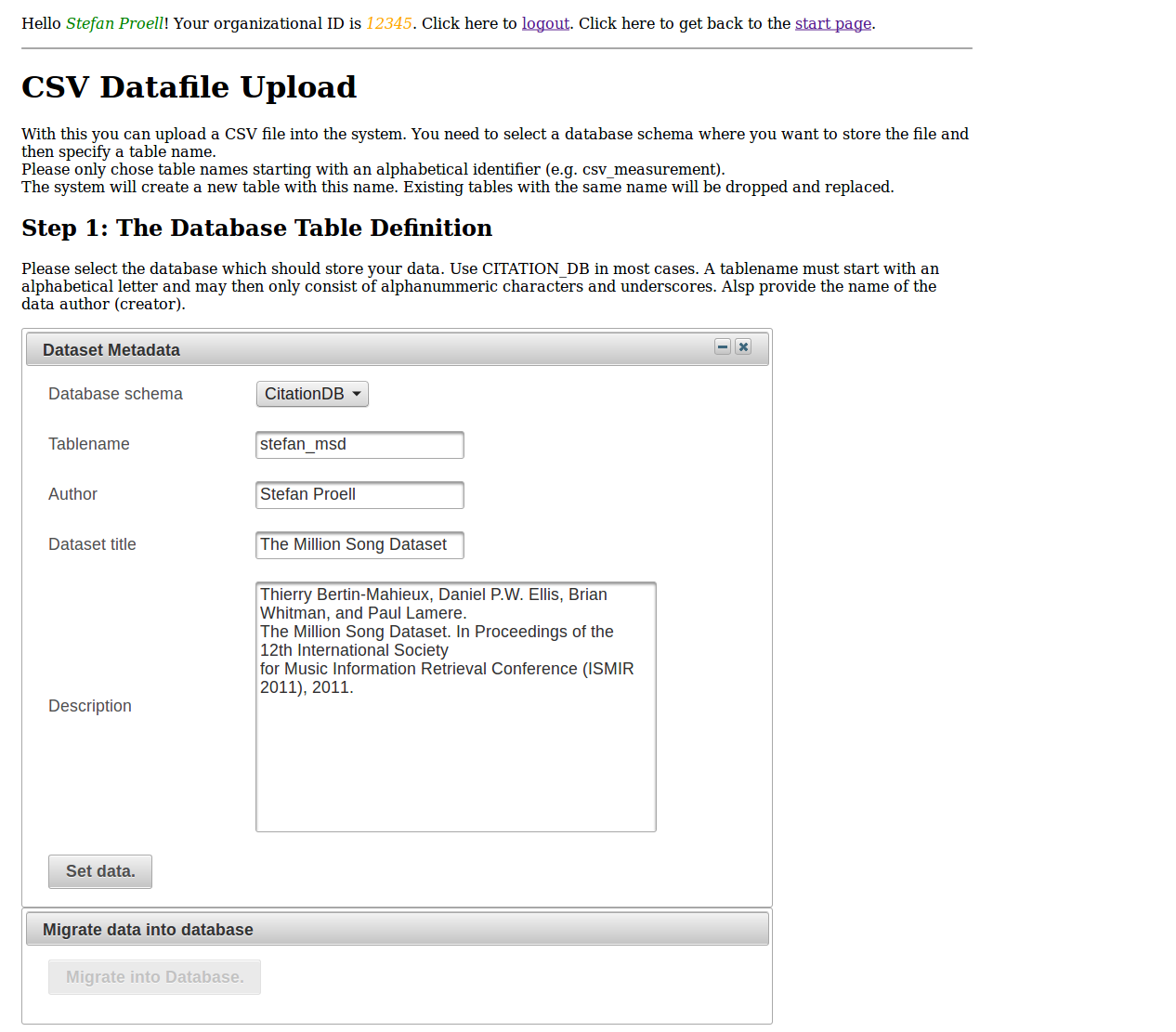
CSV File Upload
The upload of a new data file is organised in four simple steps. In the first step, users provide metadata for the data set, such as a title, data set author and a description.
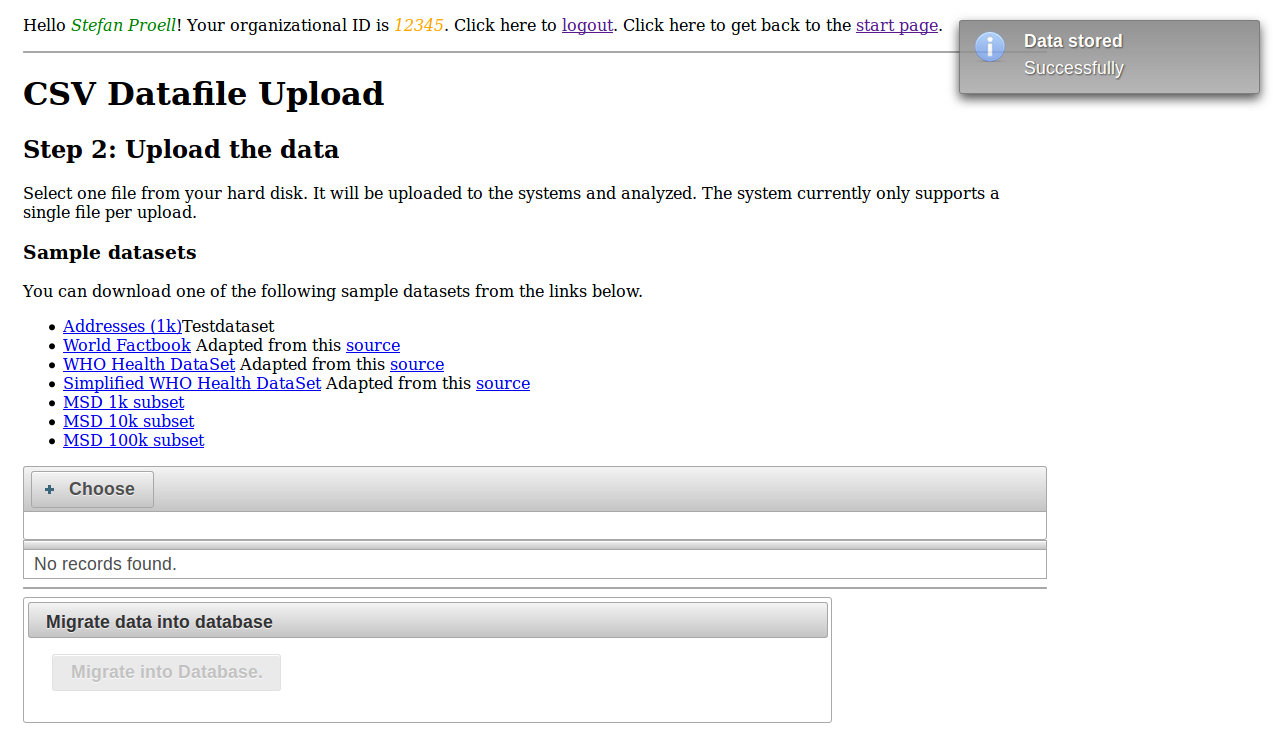
The second step is the actual upload, where the file is sent to the server.
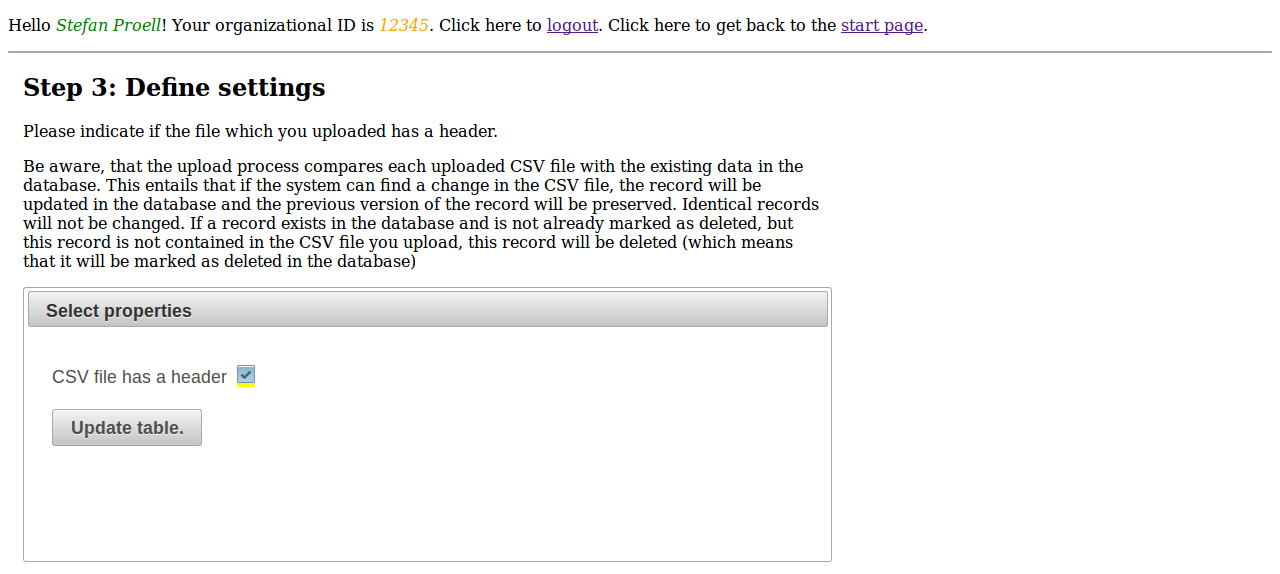
The third step is responsible for defining the column having unique values. This column serves as primary key and is responsible for differentiating between the records.
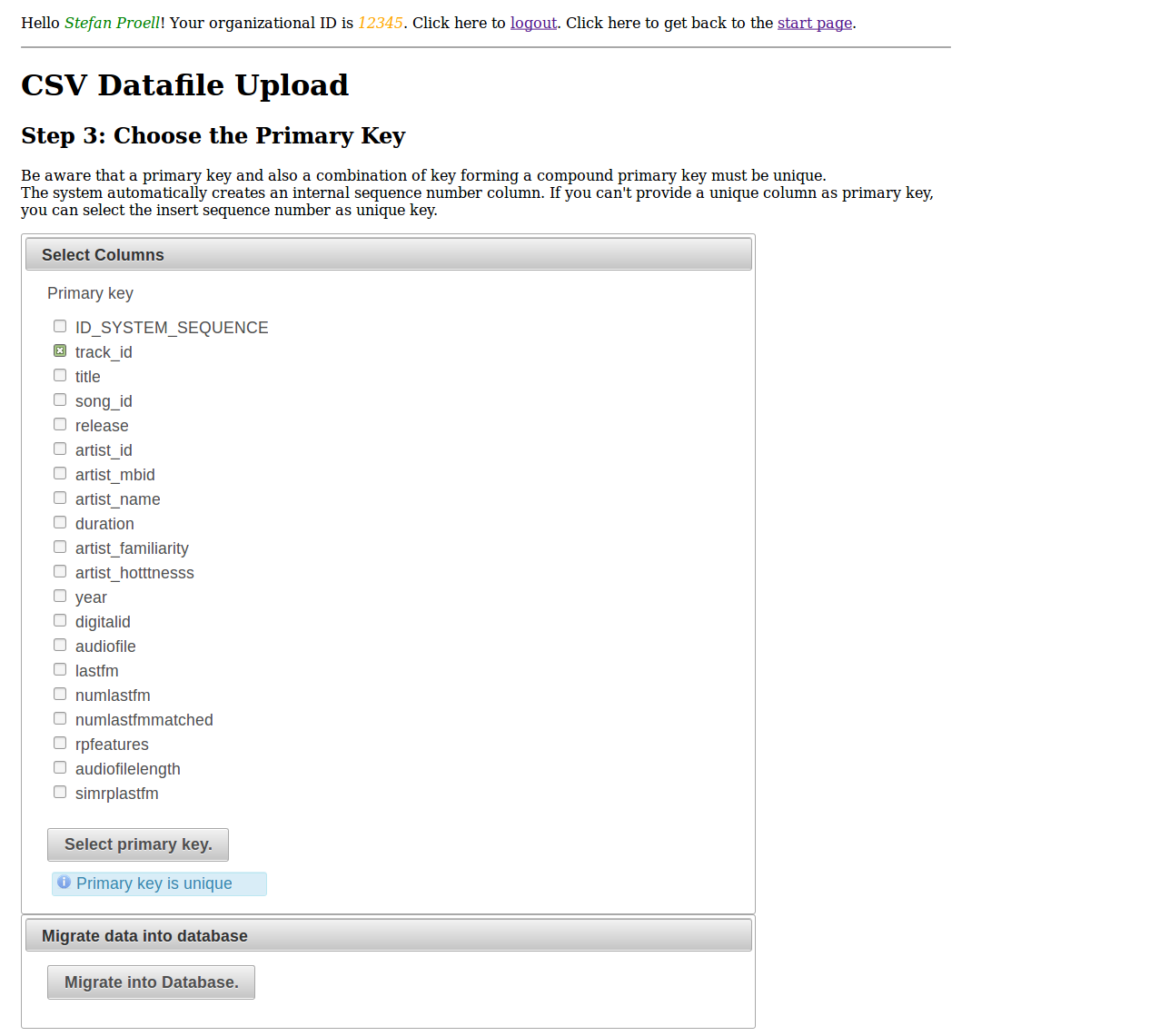
After the upload, the dataset is available for referencing and citing via a PID. The system provides the link to the dataset’s landing page.
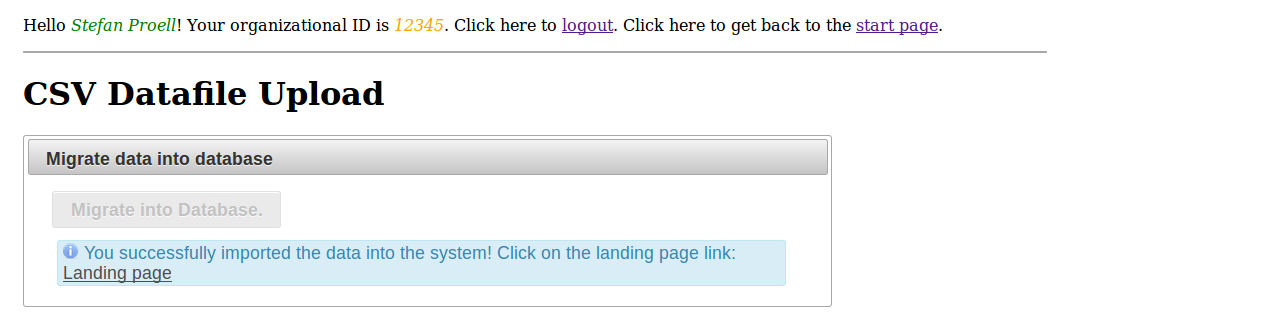
Update Existing Datasets
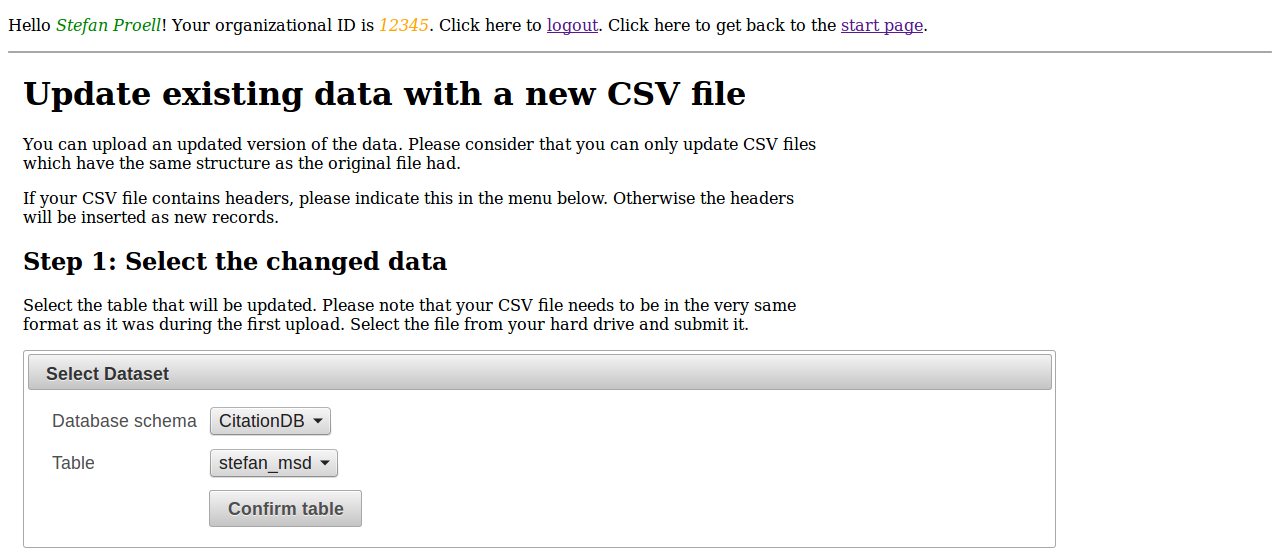
Users can update existing datasets, by re-uploading the file with the changed records. Missing records will be marked as deleted, new records are inserted and updated records are versioned.
The user selects the data she wants to update
.
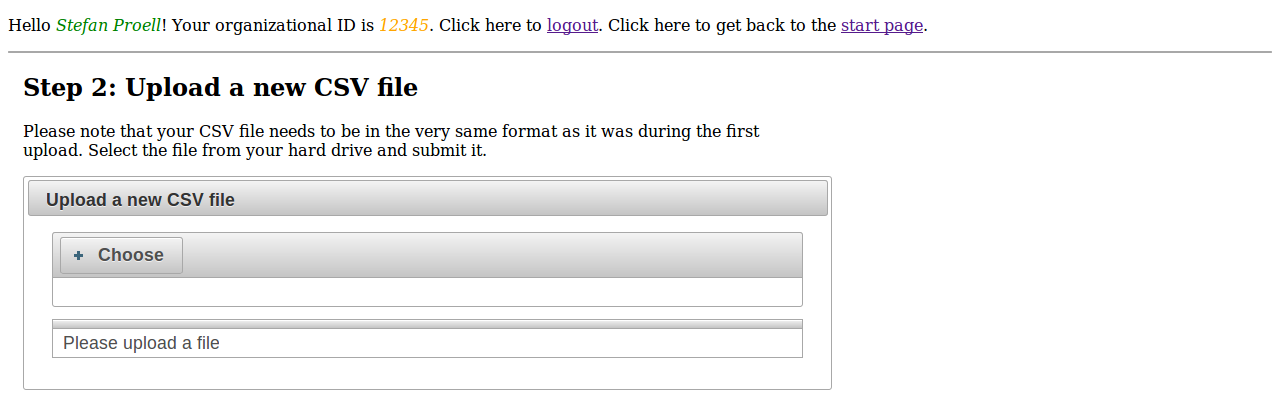
In the second step, the new file is uploaded. The columns have to match the ones that already exist in the dataset.
.
The system analyses the file and incorporates the changes.
.
Resolver and Landing Pages
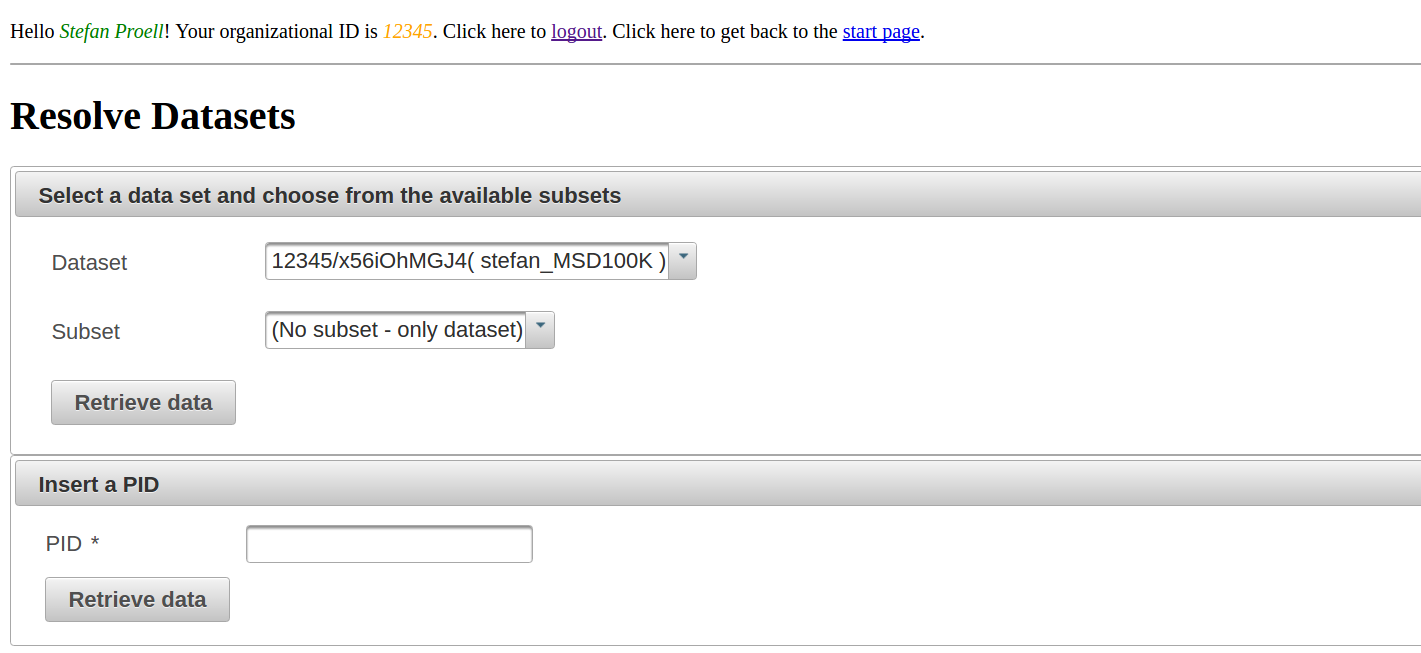
Each dataset and each subset gets a unique persistent identifier assigned. These can be resolved by the system, which then presents a landing page.
Users can select datasets and subsets from a drop down list or provide a PID.
.
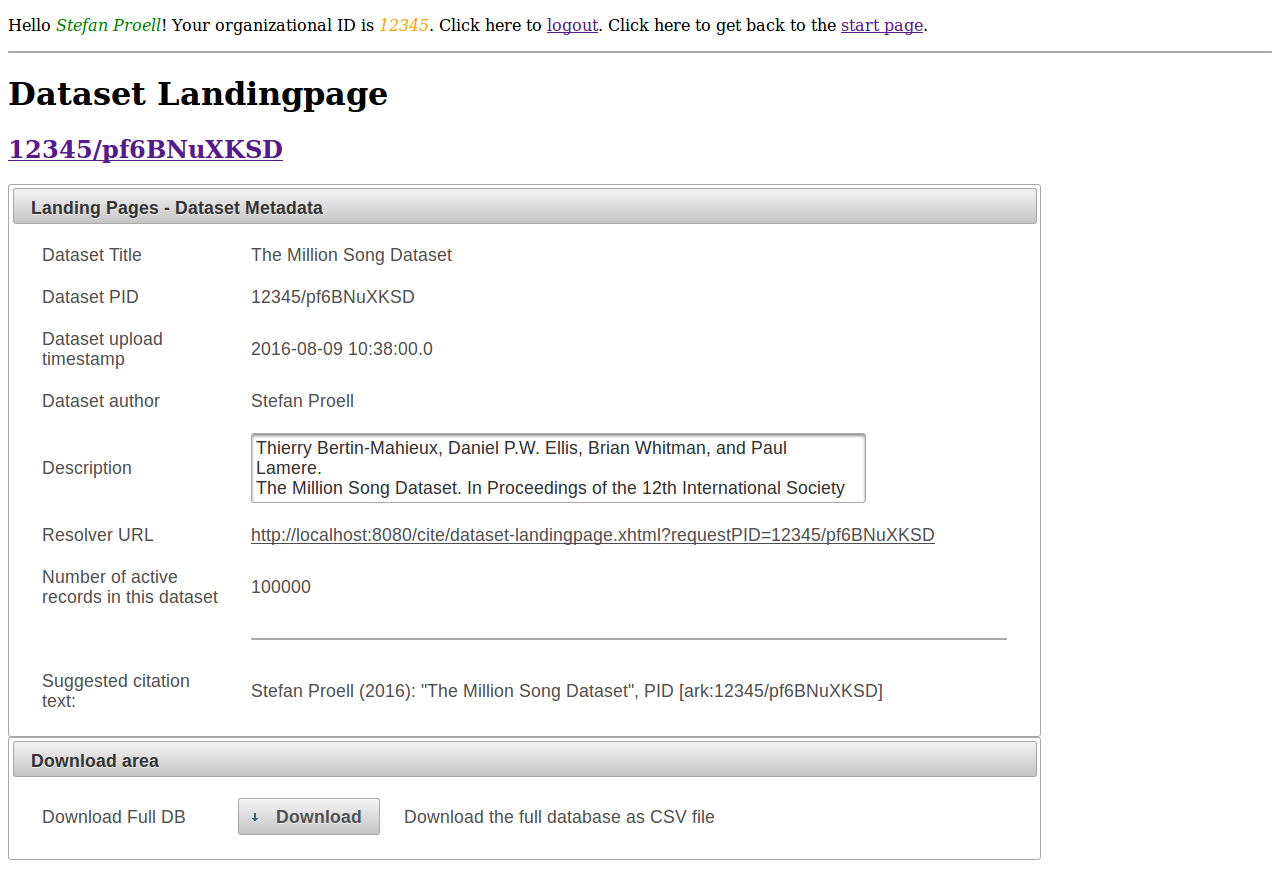
Each dataset has its own landing page, which is dynamically created from data provided by the query store.
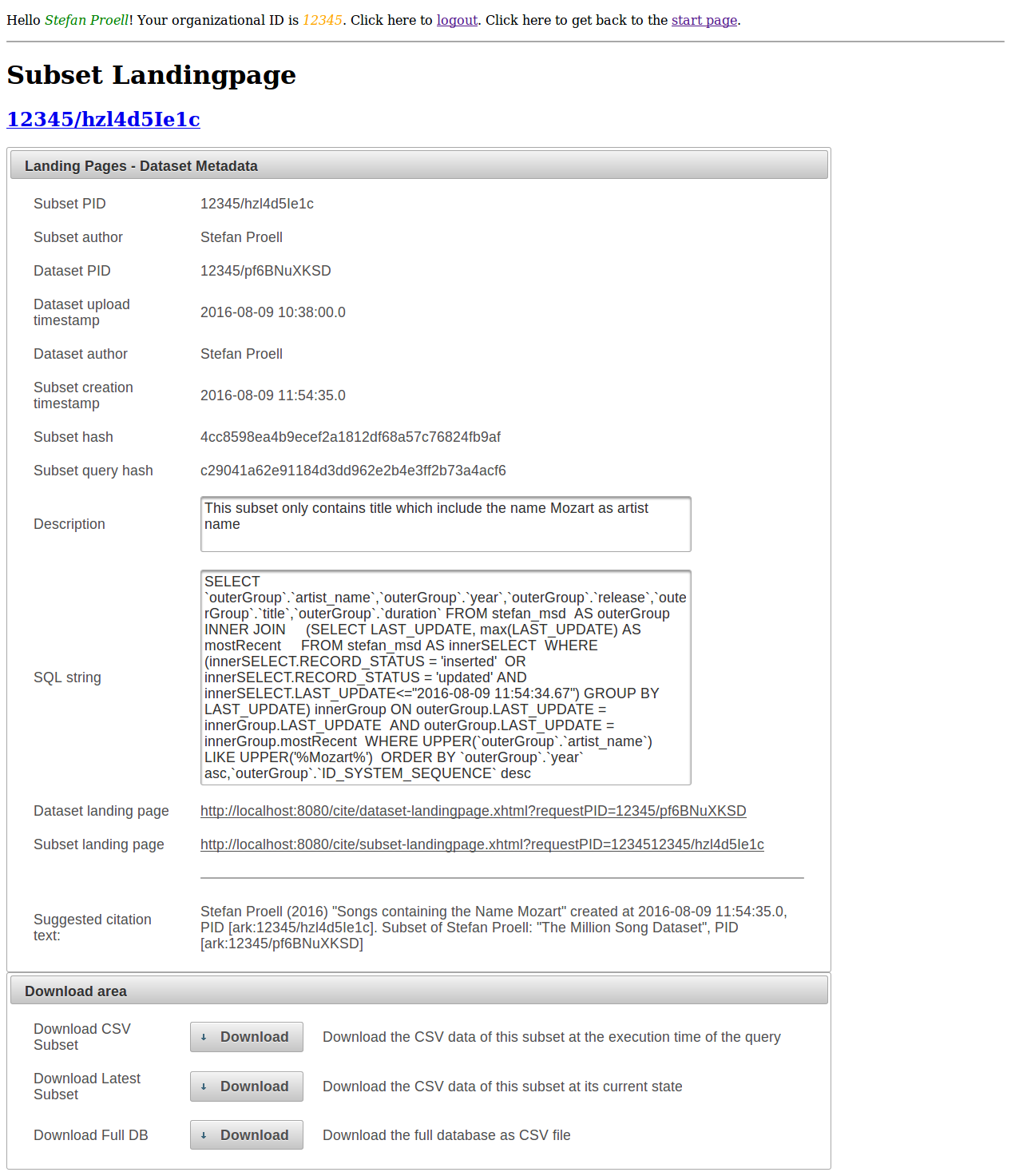
Also each subset has its own landing page, which is dynamically created from data provided by the query store.
Log in to reply.